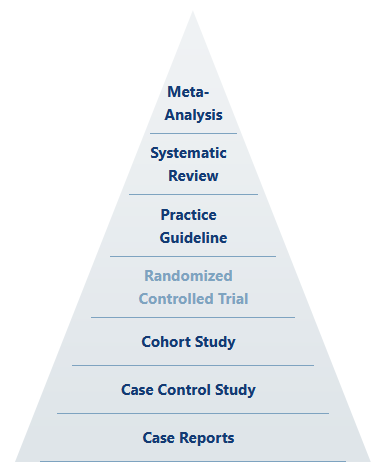
Up front, we should understand that even in the hierarchy of scientific evidence, holistic meta-analysis based on systematic review sits above the "gold standard" as something like the ultimate standard.
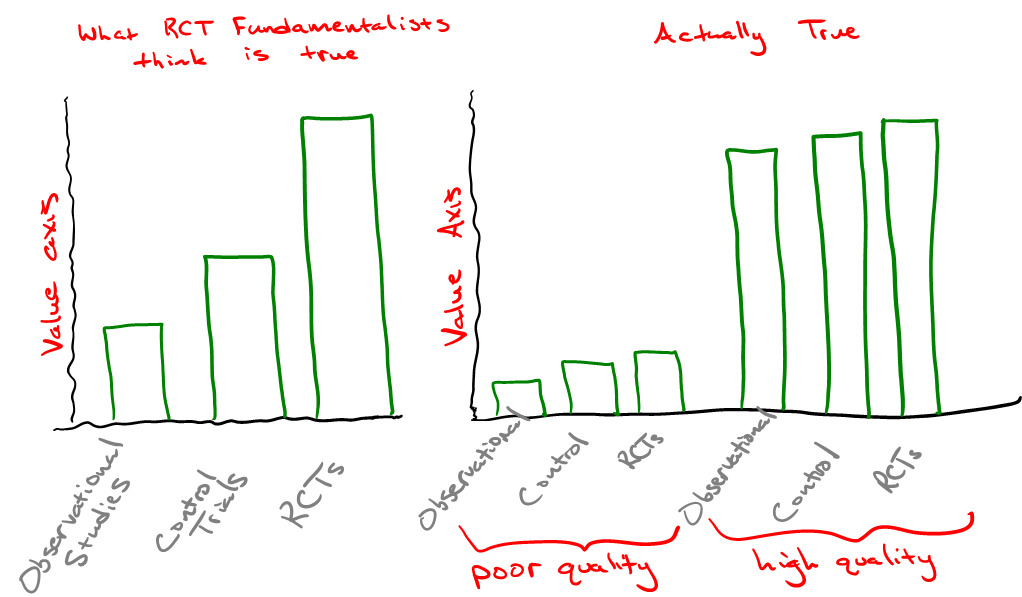
Any well-ordering of evidence inherently rests on the experimental qualities of design, execution, and analysis. That is to say that the most able, statistically-minded, highly imaginative and totally rigorous scientist (whose actions define the level of quality of design, execution, and analysis) is the true gold standard, and perhaps their classification of results is the supreme standard. The quality of the scientist-experiment system certainly trumps mere study categorization, despite any attempt to claim Pareto improvements (which would depend on holding all other qualities constant). Well-designed cohort studies can yield excellent and utilitarian results. So too can poorly-designed or conducted RCTs fall flat. Thus, by reason alone, we should recognize that the idea of the RCT as the “gold standard” is largely rhetorical---or at least dependent on other factors. Further, there is only one place in science where RCTs are generally put on the “gold standard” pedestal (rhetorically ignoring our ultimate and supreme standards) as the one and only true path to valid knowledge, and that place is pharmaceutical medicine and its allied government and corporate branches.
Before we go much further, let’s talk more about what RCTs are and what role they play in research. First, what constitutes an RCT, and why is it believed to be so important?
Definition: A randomized controlled trial (RCT) is a scientific study of an intervention (treatment) utilizing a random sorting of a population into one pool to receive the intervention (the treatment arm) and one pool not to receive intervention (the control arm), usually given a placebo to the intervention.
RCTs designed in good faith (sadly, this qualification is necessary) aim to isolate the effects of a variable, often a therapeutic drug treatment, by attempting to control for both known and unknown confounding variables. Such effects are limited and depend on numerous factors, including the population tested and the skill of experimental design involved. As this article in the BMJ aptly notes, there are many pitfalls that can degrade the quality of, if not eviscerate the quality of an RCT entirely. Let us take a look at a sample of the infinitely many ways in which an RCT can go wrong:
The population studied should be sufficient to allow for generalization of results.
For example, a study that includes or excludes members of groups with different health profiles introduces confounders, limiting or defeating the primary goal.
The method of randomization needs to be effective.
For instance, a study that recruits over the internet may result in a lopsided age distribution, so results may not apply as well to the elderly who, two decades into the millennium, are not particularly internet savvy. A study that recruits on a college campus skews toward young, conscientious students whose distribution of health profiles cannot be expected to look similar to the general population's. A study that pays for participation might net greater proportions of participants desperate for income, which may be due to causal variables that load the experimental data in ways both recognizable or unrecognizable.
In reality, effectiveness of randomization is itself an unsolvable problem. Sometimes researchers first partition a population so that randomization of participants relatively equalizes a known confounder into the two arms. However, this variation of the process has no effect on unknown confounders, which are often the larger difference between RCTs and simpler control or even observational trials. What good is a gold standard if you don't mine the gold?
The randomization method must also be well concealed from the participants.
The investigator(s) must be blinded to treatment allocation. (double blinding)
The motivations and biases of the investigator should not be introduced as a problematic variable.
Analysis must focus on testing the research question that led to the trial.
If we allow researchers to follow the results of a trial, they may be tempted to alter the hypothesis on which they report. This may be done for many reasons from raising money, seeking glory, confirming biases, or steering a narrative.
Subjects should be followed up with to the degree that desired data gets fully recorded.
If observation of the trial arms ends at 14 days, but progress between the trial arms diverges at a later time, the RCT can only be viewed as limited in its studied results. There is no limit to how greatly this might affect the outcomes we care about.
Along these lines, we might add 5(b): the framework for the analysis of the data should be chosen ahead of time wherever possible in order to limit investigator-driven bias.
Most other problems that apply to other forms of experiments also apply to RCTs.
And these are equally unenumerable. They include the way the recorded data gets measured. Is it self-reported? Surveyed by a questionnaire or by a physician? Are there pressures that steer the data in known or unknown ways?
With so many ways to miss the mark of amassing quality and actionable data, we must delve into the details of each experiment. Even then we make our subjective judgments as to the quality of data, and how we hope to analyze it. Sometimes the framework of the analysis is the more important factor. At the very least, we might establish a practical credo, such as
Regardless of all else, seek ways to make the greatest net value out of all data.
Such a credo appropriately recenters scientific perspective away from the inappropriate binary application of the so-called "gold standard", focusing it back where it belongs: the supreme and ultimate standards of science.
After this fundamental analysis of preferred standards, you might be wondering, "Okay then, but what does history tell us about the quality and value of RCT data relative to data sources?" And you would be right to ask such a question, which is where the next edition of The Chloroquine Wars will focus.
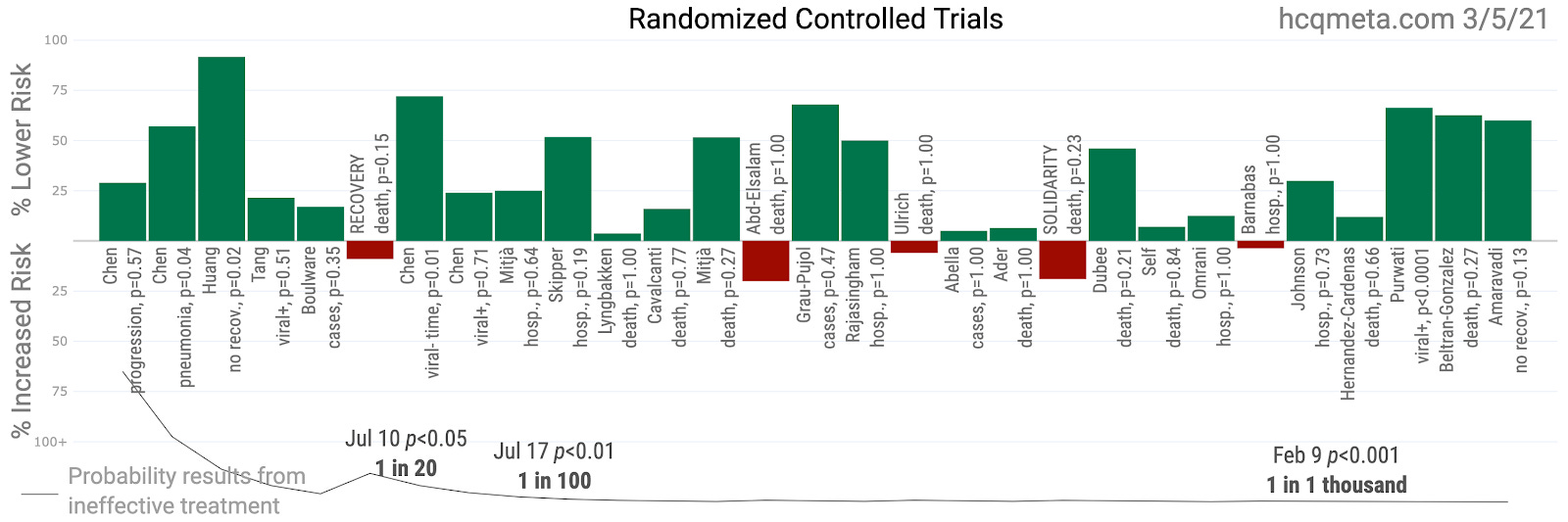
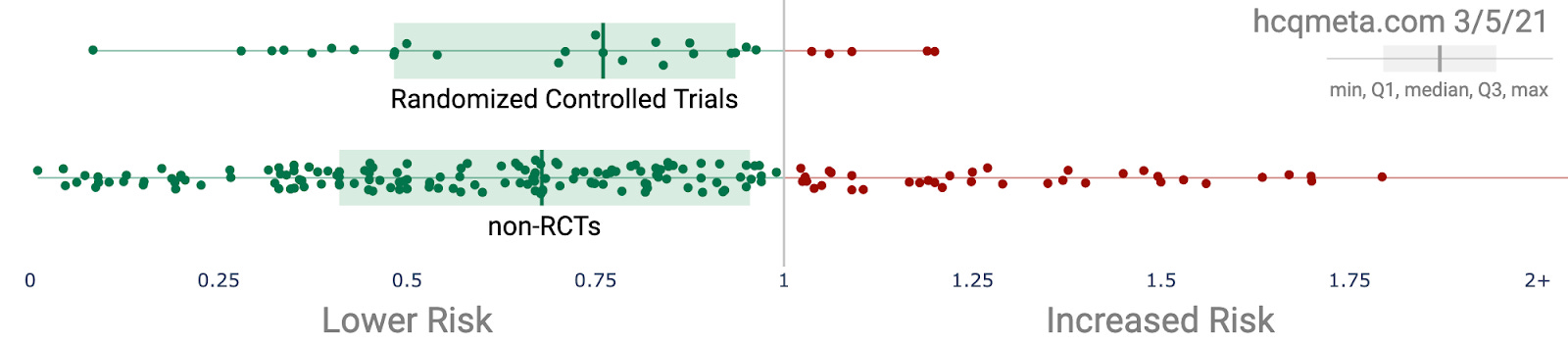
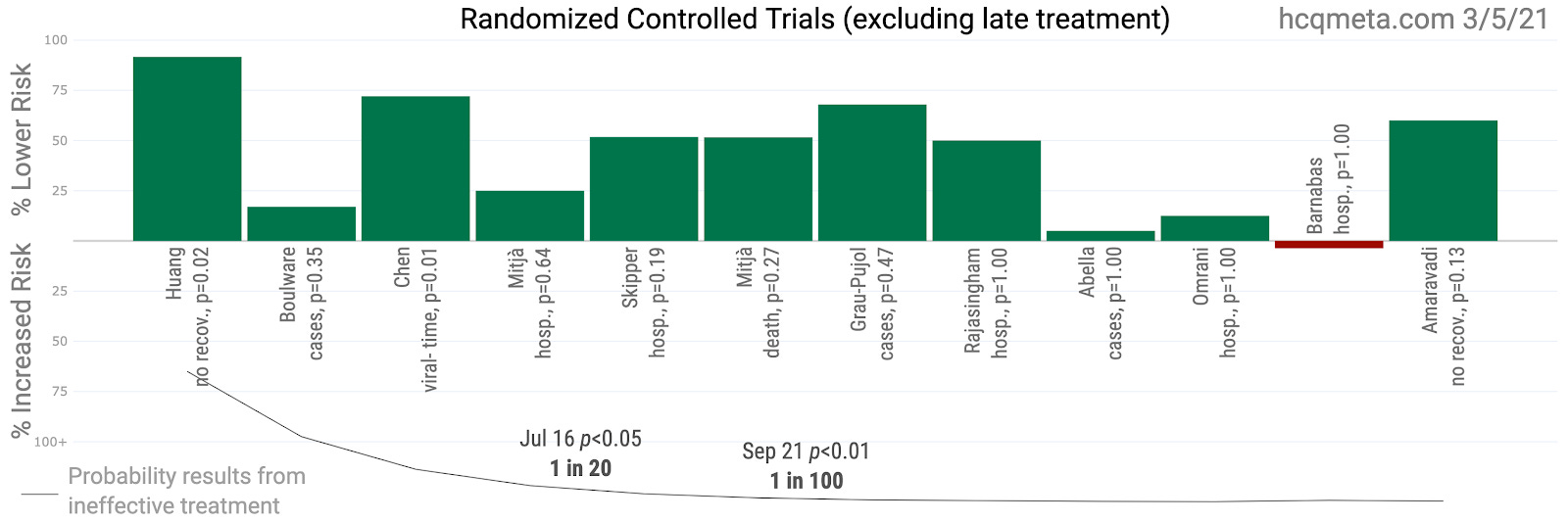
Interestingly, the distribution of results from these 29 RCTs to date looks an awful lot like the results from all other studies!
However, it makes the most sense to focus our primary attention on the most reasonable treatment protocol, which takes into account that SARS-CoV-2 replication largely ends after the first few days of symptoms. This prioritizes early treatment studies.
If the argument rests on "RCTs as the gold standard", there is little doubt that the evidence dramatically favors using HCQ as a standard early stage therapeutic! But it is reasonable to assess the quality of all the evidence to reach beyond gold for the ultimate and supreme standards of scientific evidence. That too we plan to present in future articles.